HARP - HPC Application Runtime Predictor
Overview
Researchers use high-performance computing (HPC) cyberinfrastructures (CI) like the Ohio Supercomputer (OSC) or Texas Advanced Computing Center (TACC) to execute computationally intensive diverse scientific workflows. Some workflows are heavy on IO, like genome sequencing (cleaning and assembly), while others, like training DNNs, could be compute (and memory) intensive. Each workflow has a unique resource requirement, and it is essential to profile and understand these needs to allocate shared resources for optimal utilization of the cyberinfrastructure. These resources are expensive, and several jobs compete to get these allocations, sometimes with reasonable wait times (while requesting enormous resources for a long time). Estimating the expected resources for optimally utilizing the compute and memory is challenging, especially considering the need for sufficient history to enable these predictions tailored for unique workflows and execution environments. We explored and established a framework (as shown in Figure 1) that pipelines the solutions to address these challenges. The Framework is configured to generate a history of executions and train suitable regression models to estimate the approximate execution time for a targeted application.
![]()
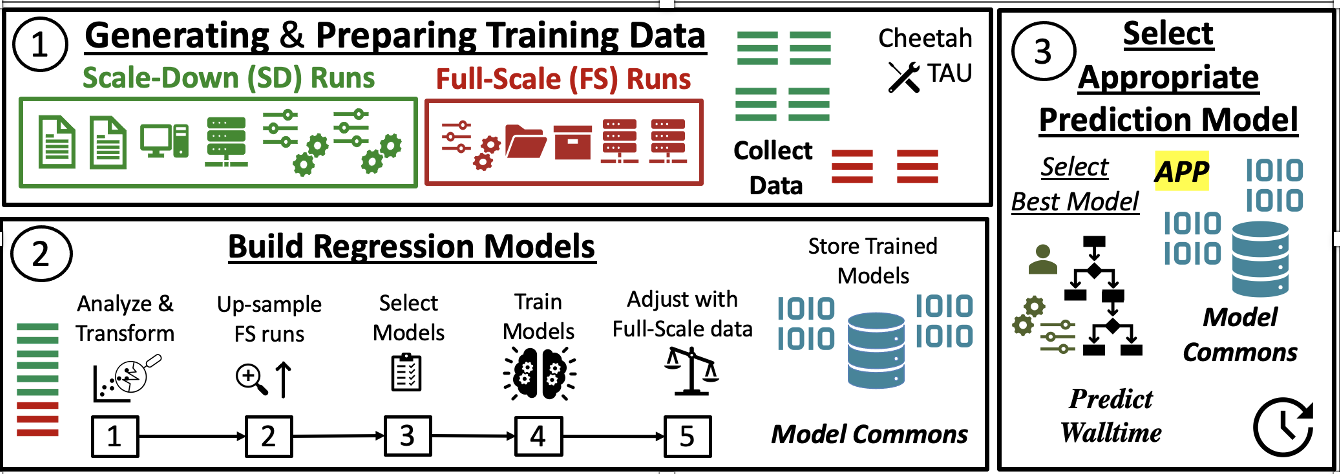
Figure 1: The Proposed Framework: training data generation, building regression models, selecting the best model based on custom criteria
Components and Characteristics of the Framework (from Figure 1):
-
Generating and Preparing Training Data: This module automatically and systematically generates comprehensive, diverse "scaled-down(SD)" and limited, selective "full-scale(FS)" runs with minimal human intervention. We use Cheetah (https://github.com/CODARcode/cheetah) to execute the target application with the pre-defined data generation configurations (SD and FS) to generate the history-of-runs training data.
-
Building Regression Models: This module standardizes and prepares the data, trains the selected off-the-shelf regression models with the appropriate hyper-parameters, and stores them for inference. In this phase, the data generated in the first phase is processed to train regression models. Redundant features are eliminated, outliers are removed, and features are transformed to reduce the dimensionality before training the regression models.
-
Selecting Appropriate Prediction Model: This module selects the most appropriate regression model from a pool of trained models from phase 2 with respect to a given policy and target application Note: The Framework is built on TensorFlow Framework.
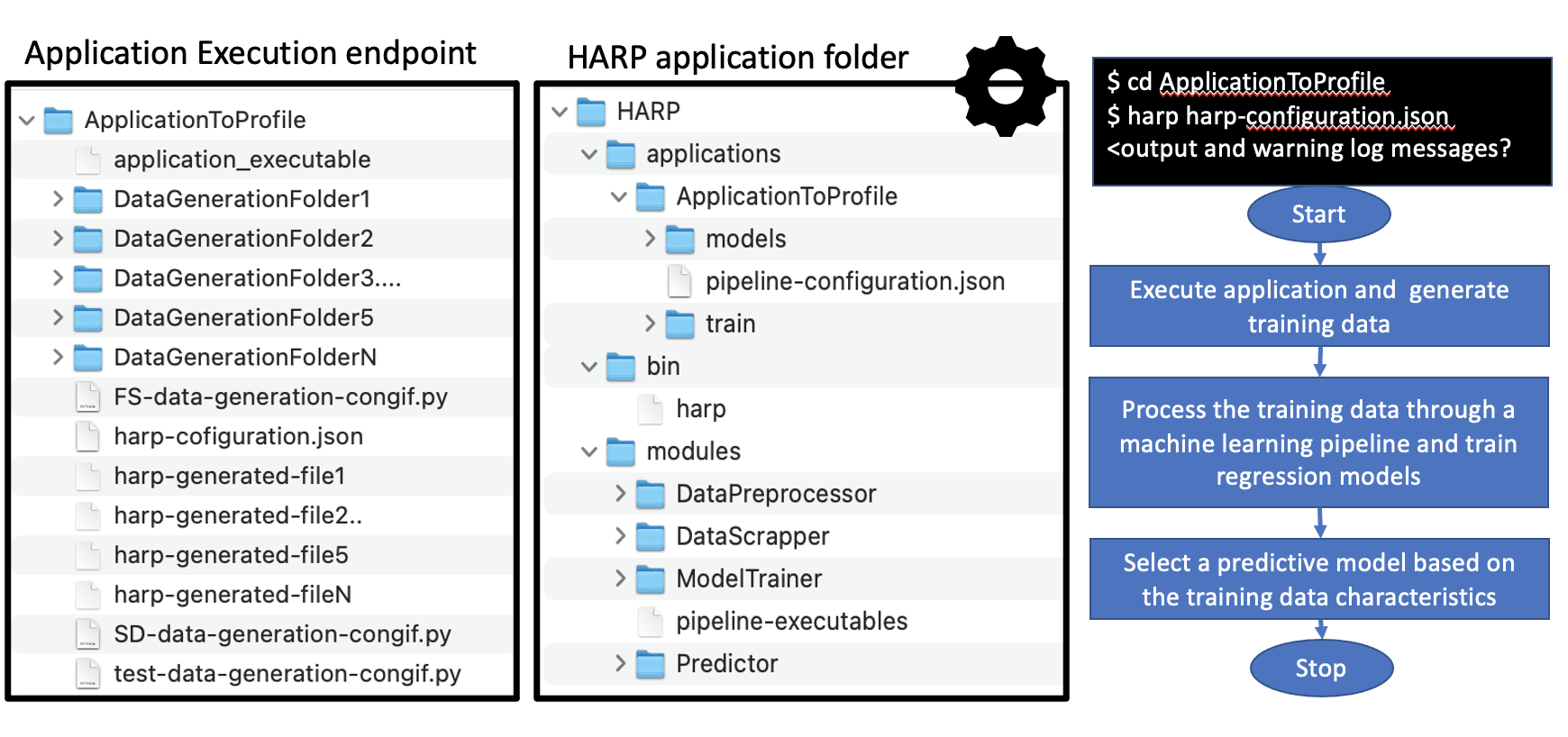
Figure 2: Shows the target-application execution endpoint and the harp application folder structure.
Citing HARP
Please cite the following paper if using HARP:
S. Vallabhajosyula and R. Ramnath, "Establishing a Generalizable Framework for Generating Cost-Aware Training Data and Building Unique Context-Aware Walltime Prediction Regression Models," 2022 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Melbourne, Australia, 2022, pp. 497-506, doi: 10.1109/ISPA-BDCloud-SocialCom-SustainCom57177.2022.00070.
Other papers: Vallabhajosyula, Manikya Swathi, and Rajiv Ramnath. "Towards Practical, Generalizable Machine-Learning Training Pipelines to build Regression Models for Predicting Application Resource Needs on HPC Systems." Practice and Experience in Advanced Research Computing. 2022. 1-5.
Reporting Bugs and Contribution
Please open an issue on the github issues page to report a bug or email vallabhajosyula.2@buckeyemail.osu.edu (with subject "HARP GitHub")
HARP is an open-source repository, and we invite the community to collaborate and include their workflows into the Framework to profile their applications. Create a pull request to add your changes to the dev branch.
SUBSCRIBE to ICICLE discussion mailing list at https://icicle.osu.edu/engagement/mailing-lists
License
The HARP is licensed under the https://opensource.org/licenses/BSD-3-Clause
Acknowledgements
This work has been funded by grants from the National Science Foundation, including the ICICLE AI Institute (OAC 2112606) and EAGER (OAC 1945347)